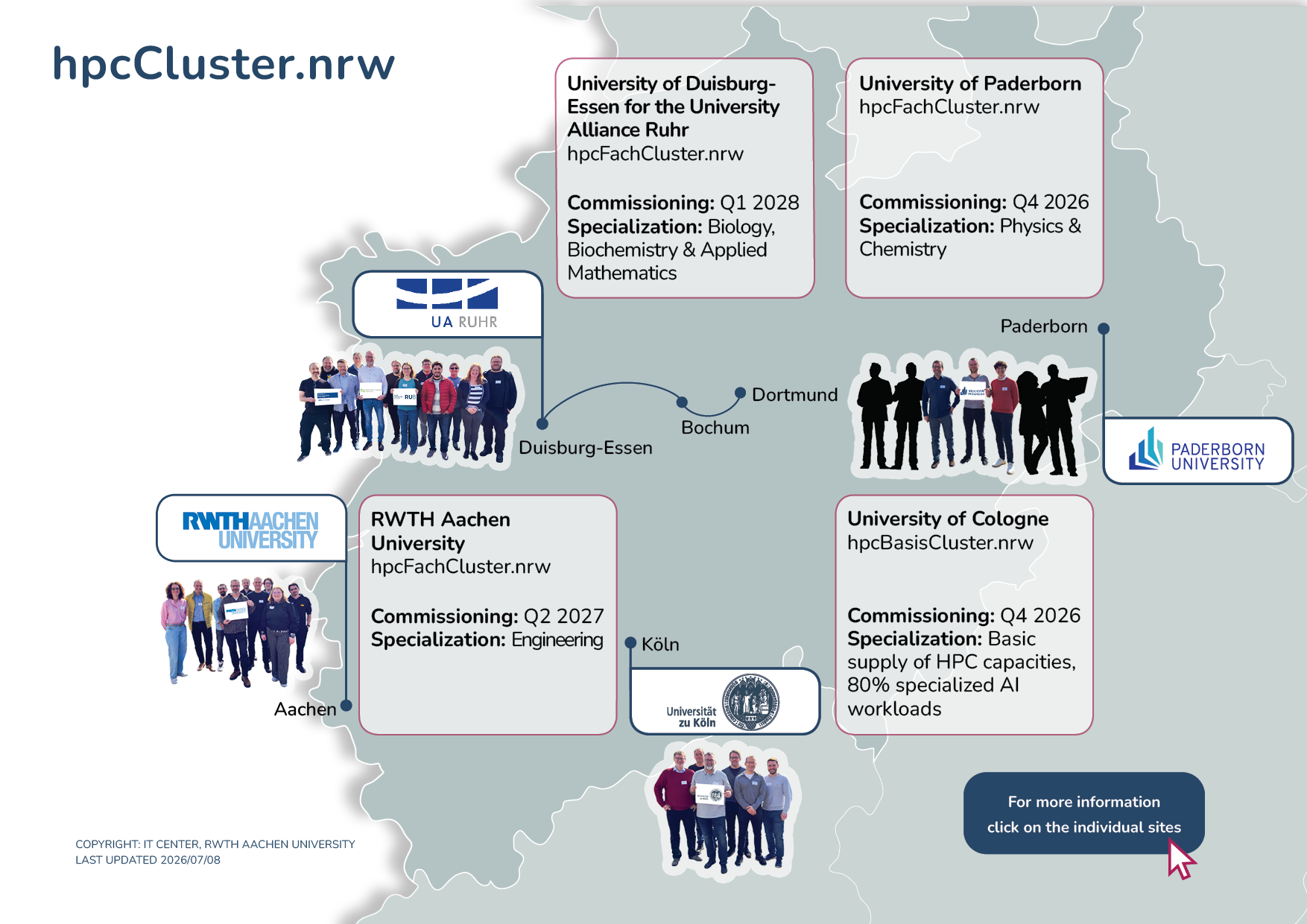
The hpcBasisCluster.nrw provides high-performance computing (HPC) capacities for universities that do not have their own Tier-3 system or that wish to cover their additional computing needs. This shared HPC cluster is intended to offer a cost- and energy-efficient alternative to setting up numerous smaller local systems.
It is being established and operated at the University of Cologne and serves as a basic supply of HPC capacities. The cluster is designed to provide low-threshold access to HPC resources and thus complement the existing digital ecosystem for HPC in the state.
The system will allocate 80 percent of its resources to dedicated AI workloads. Universities had the opportunity to acquire usage rights in advance; the expressions of interest for the first deployment phase have already been completed. The cluster is scheduled to go into operation in the fourth quarter of 2026. A second expansion phase is planned for 2027.
The authorized user institutions are structured by deployment phase as follows:
| hpcBasisCluster 1 | hpcBasisCluster 2 |
| Heinrich Heine University Düsseldorf | Heinrich Heine University Düsseldorf |
| Bielefeld University of Applied Sciences | Ruhr University Bochum |
| University of Wuppertal | Niederrhein University of Applied Sciences |
| Münster University of Applied Sciences | University of Duisburg-Essen |
| Rhine-Waal University of Applied Sciences | University of Siegen |
| Ruhr University Bochum | University of Bonn |
| Niederrhein University of Applied Sciences | Aachen University of Applied Sciences |
| Düsseldorf University of Applied Sciences | Ruhr West University of Applied Sciences |
| University of Münster | University of Cologne |
| Westphalian University of Applied Sciences | Westphalian University of Applied Sciences |
| University of Duisburg-Essen | |
| University of Siegen | |
| TH Köln | |
| OWL University of Applied Sciences and Arts | |
| RWTH Aachen University | |
| TU Dortmund University | |
ATTENTION: ERROR IN THE COST CALCULATION
An error occurred in the original calculation of the operating costs. The corrected calculation is as follows:
“Based on an operating time of 8,640 hours per year with five days of maintenance, the annual operating costs would amount to €950,460.48. With a personal contribution of €15,000 investment, the resulting annual operating costs would be €17,281.10. This corresponds to approximately 1.82% of the total system (including the state’s share).”
Please note that these operating costs are an estimate based on our previous experience. The final billing will be carried out according to the actual electricity consumption and will be proportionally allocated through a fair-use settlement.
Should the "AI/GPU Nodes: AI Training" GPUs also provide efficient support for double-precision calculations?
The market is currently evolving in such a way that double-precision calculations are increasingly considered a lower priority by the vendors. In general, however, these GPGPUs still support efficient DP64 operations. Please include this requirement in the demand survey so that it can be taken into account.
Can the GPU nodes in the cluster provide larger server configurations with 8 GPUs per node, and how is the architecture of these nodes designed?
In Phase 1 of the hpcBasisCluster.nrw GPU nodes with 8× B200 GPUs per node will be provided. This meets the requirements of large models and workflows, where limitations due to memory bandwidth are significant, which is why larger servers with 8 GPUs per node are preferred over 4 GPUs per node.
The nodes are high-cost, as they use a “DGX-like” architecture in which the GPUs are closely coupled and share access to the memory. This enables efficient processing of large models, as required, for example, on the currently available 5 servers with 8× A100 (40 GB) GPUs each.
Is it already clear whether Nvidia or AMD GPUs will be procured?
It is not possible to anticipate the outcome of the tender at this stage. The focus is expected to be on NVIDIA, but AMD will also be considered, as their cards offer more memory, which often constitutes the bottleneck when running large networks. AMD has also made significant progress in the software stack over the past 6 to 9 months.
Are the simulation nodes (CPU) operated with blocking or non-blocking InfiniBand?
The nodes are now powerful enough that many jobs with up to 192 CPU cores can run on a single node and therefore operate in a non-blocking manner. The current phase 1 base cluster is assumed to have a non-blocking architecture.
For the upcoming expansion, large workloads that exceed the island sizes are expected to require a pruning factor of at most 1:3. As long as execution remains within an island, non-blocking performance should also be achieved.
Are the GPU nodes also connected via an InfiniBand network?
CPU and GPU nodes are connected via a shared interconnect. InfiniBand is one possible option, but there are equivalent alternatives such as OmniPath, as well as various solutions based on Data Centre Ethernet that offer comparable performance. The goal is an interconnect with low latency and homogeneous communication.
Which central storage system is planned for use, and how much storage will be available?
The tender is issued openly. Currently, SpectrumScale/GPFS is in use, but alternatives such as Lustre, PanFS/Vdura, as well as Weka and VAST are also being considered. The system is also intended to be connected to the object storage systems DataStorage.NRW and DataArchive.NRW (currently under development) for “warm data.” T
he total available storage of the system is estimated to be approximately 2 to 4 PB. A more precise assessment of requirements will allow for better planning of the necessary resources for the storage system and for the scenarios to be supported.
Do you provide options for long-term data storage?
In North Rhine-Westphalia, this is supported via DataStorage.NRW (already available) and DataArchive.NRW (under development). However, this is not an objective of the hpcBasisCluster.nrw.
What options are available for fulfilling software requirements on the hpcBasisCluster.nrw?
As a rule, the purchase of software is not provided for in the hpcBasisCluster.nrw. The possibilities for bringing in custom software must be discussed on a case-by-case basis. Implementation should, however, be feasible
Is it planned that each participating university will receive a Slurm account, through which subaccounts or projects for the respective users can be created independently, or is another procedure planned?
The exact technical implementation has not yet been determined, but the approach is basically as planned: Each university will be able to manage a share of the cluster corresponding to its investment. Account validation will likely be carried out via a Regapp instance (e.g., https://www.scc.kit.edu/dienste/regapp.php), while the allocation of compute time to individual users will be managed by the respective university.
The goal is to make the allocations as flexible as possible, so that minimal compute time goes unused. If individual sites do not use their allocations at certain times, other sites can utilize the additional resources during that period.